Tras el parón de las navidades, vuelven los post técnicos al blog. En esta ocasión vamos a hablar del web scraping (o scraping, a secas) y veremos una pequeña aproximación a esta técnica.
El scraping es una técnica que nos permite extraer datos de sitios web de manera automatizada. Es decir, nos permite recorrer un sitio web y recopilar información del mismo de forma desasistida. Sin embargo, hay que tener en cuetna sus limitaciones legales y éticas.
Limitaciones Legales
El scraping en sí mismo no es ilegal, pero su práctica puede involucrar aspectos legales y éticos que es necesario tener claros.
1. Términos de Servicio del Sitio Web
Hay que revisar las condiciones de servicio del sitio web que planeamos analizar. Algunas webs prohíben expresamente esta práctica, mientras que otraspueden permitir su uso bajo ciertas condiciones. Hay que tener en cuenta estas condiciones de uso siempre.
2. Acceso No Autorizado
Si la web requiere autenticación y accedemos a áreas protegidas sin permiso, estamos incurriendo en acceso no autorizado. Esto puede tener implicaciones legales y éticas significativas.
3. Impacto en el Servidor
El scraping puede llegar a aumentar la carga en los servidores del sitio web, afectando su rendimiento. Esta práctica puede considerarse una violación de las condiciones de uso si se realiza de manera excesiva.
4. Uso Ético de la Información
Aunque el uso de esta técnica sea legal, en un determinado sitio web, hemos de tener en cuenta que uso vamos a hacer de los datos que recopilemos. Si vamos a acceder a datos personales de terceros, es mejor olvidarnos de todo.
Veamos un ejemplo práctico
Vamos a ver un ejemplo utilizando Python. En este caso, extraeremos los enlaces de la página principal de este sitio web y se guardarán en un fichero csv. Es importante indicar que en el ejemplo que os propongo, el análisis solo se efectua de página en página, es decir, que no se navega por todo el arbol de directorios del sitio web.
Se ha hecho así, para limitar el alcance del ejemplo y proponer un caso práctico lo más «blanco» posible.
Aquí está el código:
# Importamos las librerias necesarias
import requests
from bs4 import BeautifulSoup
import csv
# URL objetivo
url = 'https://www.paginadeejemplo.es'
# Realizar la solicitud HTTP
response = requests.get(url)
# Verificar si la solicitud fue OK (código 200)
if response.status_code == 200:
# Obtener el contenido HTML
html_content = response.text
# Crear un objeto BeautifulSoup para analizar el HTML
soup = BeautifulSoup(html_content, 'html.parser')
# En este caso, recogemos todos los links <a> de la página objetivo
links = soup.find_all('a')
# Crear un archivo CSV para escribir los resultados
with open('resultados.csv', 'w', newline='', encoding='utf-8') as csv_file:
csv_writer = csv.writer(csv_file)
# Escribir encabezado
csv_writer.writerow(['Enlace'])
# Escribir los enlaces en el archivo CSV
for link in links:
csv_writer.writerow([link.get('href')])
# Mensaje si OK
print('Análisis completado. Resultados guardados en resultados.csv')
else:
# Mensaje si KO
print(f'Error al hacer la solicitud. Código de estado: {response.status_code}')El código es bastante sencillo y creo que a modo de ejemplo es bastante claro:
- Se determina una url de destino para nuestro análisis
- Se intenta la conexión a la misma
- Si la conexión es OK, se analiza el código html en busca de todas las etiquetas de enlaces «<a>» y se copia el contenido en un fichero CSV
El fichero csv resultante, es algo similar a esto que podemos ver aquí
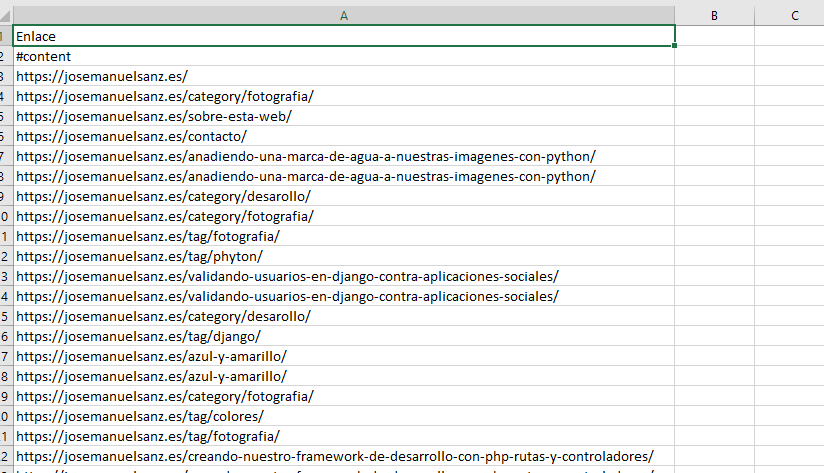
Con lo cual, hemos recopilado de forma sencilla, todos los elementos que nos interesaban de un sitio web.
Como siempre, os dejo el código en mi repositorio de GitHub para que podáis analizarlo y trabajar con el.
Disclamer: Este post, simplemente busca mostrar una técnica de recopilación de información, no debe ser usado para acceder a datos a los que no tenemos permiso.